Kỹ nghệ hệ thống Trí tuệ nhân tạo
Bài 7: Software Architecture Engineering
Kiến trúc phần mềm cho dự án AI production
Trường ĐH Công nghệ – Đại học Quốc gia Hà Nội
Nội dung chính
- Nền tảng software architecture cho hệ AI
- Monolithic và Microservices
- RESTful API, gRPC, event-driven
- Thành phần hạ tầng: LB, API Gateway, cache, queue, CDN, VPN, VPS
- Serverless, monitoring, database/storage
- Reference architecture và lộ trình triển khai
Mục tiêu buổi học
- Biết chọn kiến trúc phù hợp cho bài toán AI thật, không chỉ “model-centric”.
- Hiểu vai trò và trade-off của các thành phần kiến trúc thường gặp.
- Có thể phác thảo kiến trúc end-to-end cho một sản phẩm AI production.
1.
Nền tảng Software Architecture
Software architecture là gì?
Trong dự án AI, kiến trúc phải trả lời gì?
- Model được gọi ở đâu? theo request realtime hay batch?
- Dữ liệu đi qua những lớp nào trước khi vào model?
- Khi model sai thì hệ thống xử lý an toàn thế nào?
- Làm sao mở rộng khi traffic tăng đột biến?
Model-centric vs System-centric
| Góc nhìn | Model-centric | System-centric |
|---|---|---|
| Trọng tâm | accuracy model | mục tiêu hệ thống |
| Rủi ro | bỏ qua vận hành | quản trị trade-off rõ |
| Kết quả | demo tốt | sản phẩm chạy bền |
Chất lượng hệ thống cần cân bằng
- Latency, throughput, availability
- Scalability và cost
- Maintainability và deployability
- Security, privacy, compliance
- Observability và incident response
Một kiến trúc AI điển hình

Câu hỏi nhanh
- Bạn đang tối ưu model hay tối ưu hệ thống?
- 2 quality attributes quan trọng nhất cho bài toán của bạn là gì?
- Nếu model trả sai, hệ thống đã có cơ chế fallback chưa?
2.
Monolithic vs Microservices
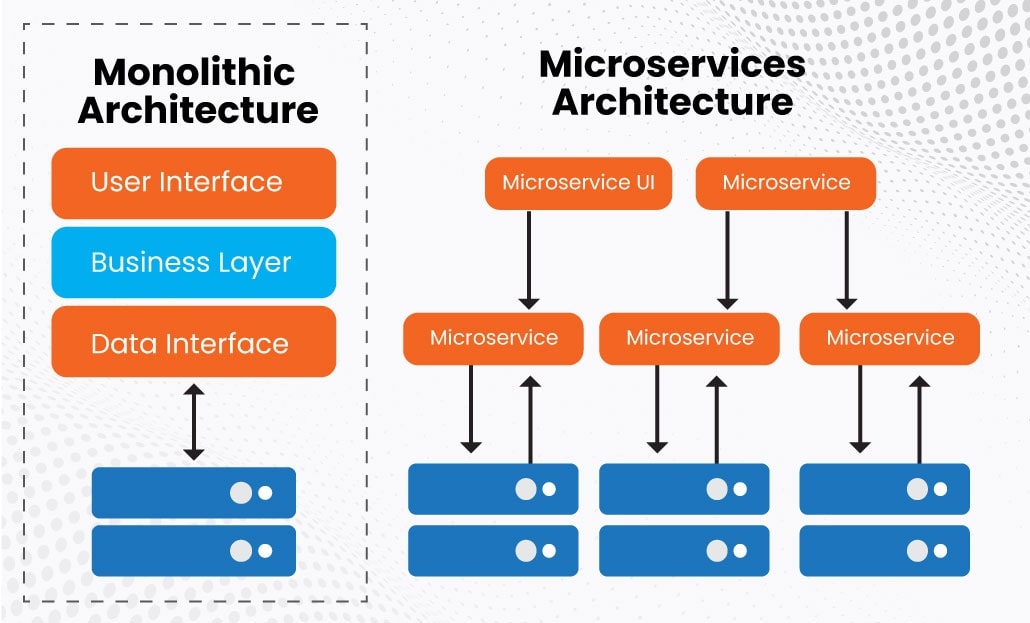
Monolithic architecture
- Một codebase/deploy unit lớn, nhiều module bên trong.
- Dễ bắt đầu nhanh khi team nhỏ, domain đơn giản.
- Debug local thuận tiện, transaction nội bộ dễ.
Ưu điểm Monolith
- Đơn giản về vận hành ban đầu.
- Ít chi phí network giữa service.
- Release ban đầu nhanh.
- Phù hợp MVP/POC.
Hạn chế Monolith
- Khó scale riêng từng phần nóng.
- Deploy một phần cũng phải redeploy toàn app.
- Coupling cao, dễ “spaghetti dependencies”.
- Khó tách ownership khi team lớn dần.
Microservices architecture
- Hệ thống tách thành nhiều service nhỏ theo bounded context.
- Mỗi service có lifecycle/deploy độc lập.
- Service giao tiếp qua API hoặc event bus.
Ưu điểm Microservices
- Scale theo chiều ngang từng service.
- Deploy độc lập, giảm blast radius.
- Dễ tổ chức team ownership theo domain.
- Cho phép polyglot tech stack.
Hạn chế Microservices
- Tăng độ phức tạp vận hành (network, observability, CI/CD).
- Distributed debugging khó hơn.
- Data consistency và transaction phức tạp.
- Yêu cầu kỷ luật kiến trúc cao.
Bảng so sánh nhanh
| Tiêu chí | Monolith | Microservices |
|---|---|---|
| Time-to-market ban đầu | Nhanh | Chậm hơn |
| Vận hành | Đơn giản | Phức tạp |
| Scale | Toàn khối | Từng service |
| Autonomy team | Thấp | Cao |
Câu hỏi nhanh
- Hệ thống của bạn đang “quá sớm” hay “đúng lúc” để microservices?
- Service nào nên tách đầu tiên nếu cần?
- Nếu không tách, bottleneck hiện tại là gì?
3.
Phương thức giao tiếp
RESTful API (HTTP/JSON)
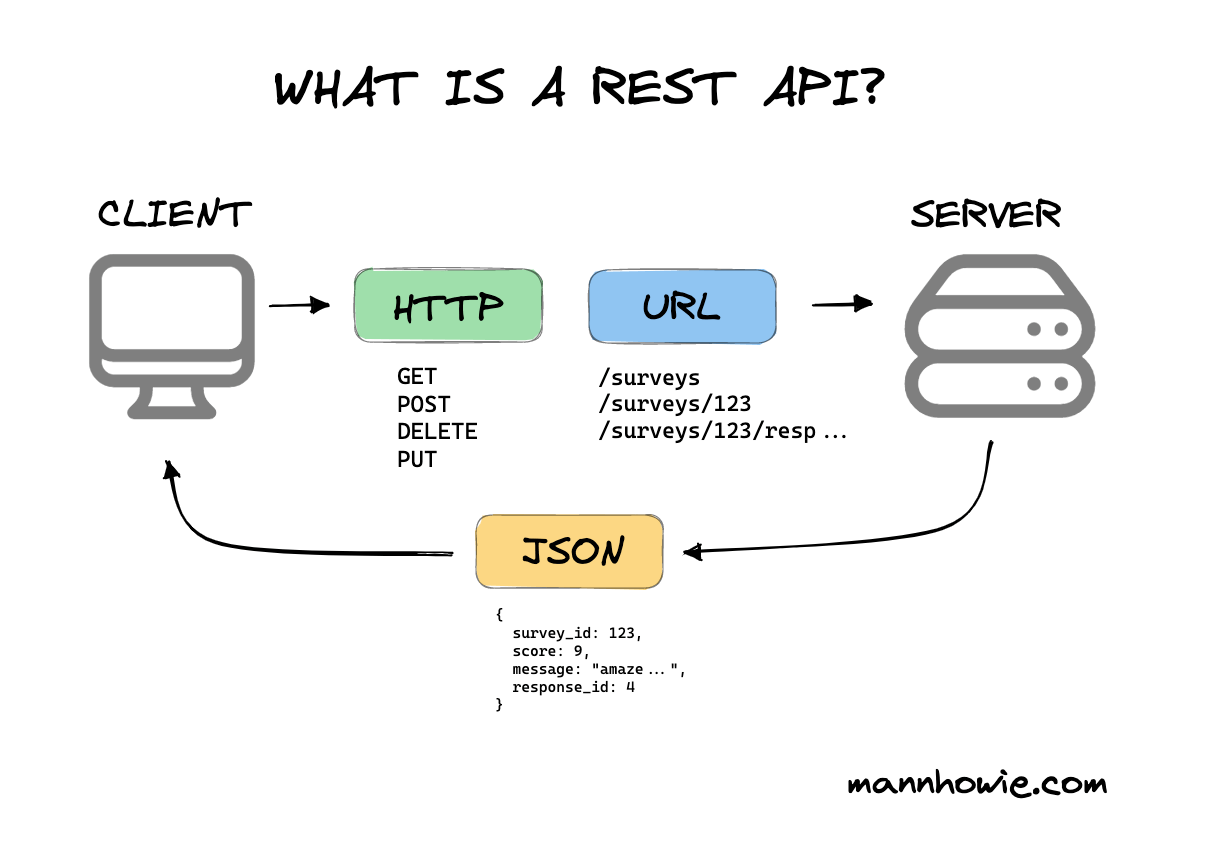
RESTful API
- Phổ biến, dễ dùng từ web/mobile/service.
- Resource-oriented: GET/POST/PUT/DELETE.
- Dễ debug qua browser/Postman/curl.
Ưu nhược điểm REST
- Ưu: đơn giản, ecosystem rộng.
- Nhược: overhead JSON lớn, latency cao hơn nhị phân.
- Phù hợp: client-facing APIs, public APIs.
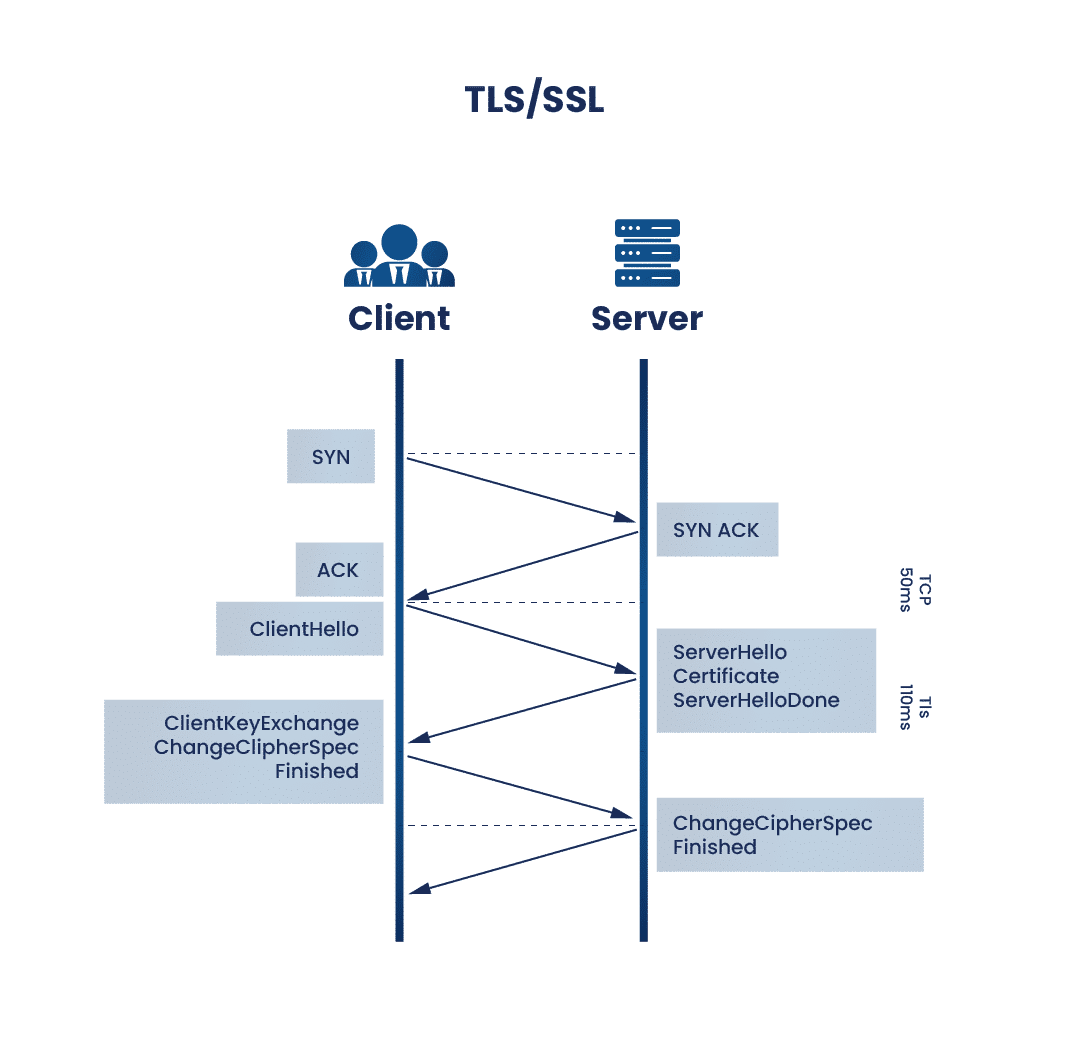
REST qua HTTPS: SSL/TLS là gì?
- HTTPS = HTTP chạy trên kênh đã được mã hóa bằng TLS (Transport Layer Security).
- SSL (Secure Sockets Layer) là tiêu chuẩn cũ; ngày nay thực tế dùng TLS 1.2 / TLS 1.3 — vẫn hay gọi chung “SSL/TLS”.
- Mục tiêu: confidentiality (bên thứ ba không đọc được payload), integrity (dữ liệu không bị sửa lén), authentication (xác thực server qua chứng chỉ).
- REST API public nên luôn phục vụ qua https:// (không gửi token/cookie trên HTTP thuần).
TLS hoạt động tóm tắt (handshake)
- Chứng chỉ (certificate): server có cặp khóa; CA ký chứng chỉ → client tin “đúng domain”.
- Handshake: thỏa thuận phiên bản TLS, bộ mã hóa (cipher suite), trao đổi khóa phiên (thường dùng ECDHE…).
- Sau handshake, dữ liệu ứng dụng (JSON REST, header…) được mã hóa bằng khóa đối xứng của phiên (nhanh); khóa công khai chủ yếu dùng ở giai đoạn bắt tay.
- mTLS (mutual TLS): client cũng có chứng chỉ — dùng nội bộ / B2B khi cần xác thực hai chiều mạnh.
Triển khai: reverse proxy (NGINX, Envoy) hoặc cloud LB chấm dứt TLS; ứng dụng có thể chỉ nhận HTTP nội bộ sau TLS termination.
gRPC (HTTP/2 + Protobuf)
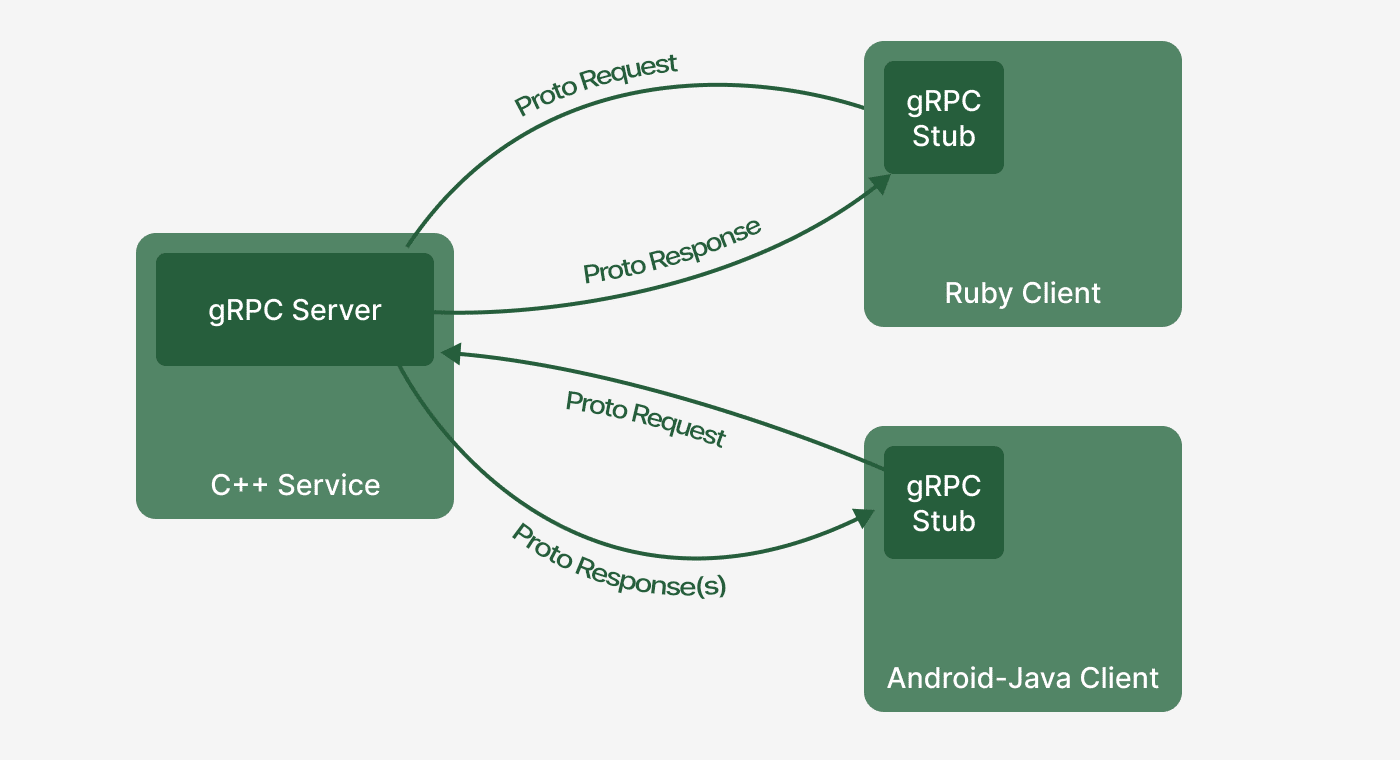
gRPC
- Nhanh, binary protocol, strongly typed contracts.
- Hỗ trợ streaming hai chiều.
- Phù hợp giao tiếp nội bộ service-to-service.
Ưu nhược điểm gRPC
- Ưu: performance cao, contract-first.
- Nhược: khó debug thủ công hơn REST.
- Phù hợp: low-latency microservices, realtime backend.
gRPC: tự động sinh code (Code Generation)
- Contract được mô tả trong file .proto (Protobuf): service, rpc, message.
- Toolchain protoc (protobuf compiler) + plugin đọc .proto → sinh stub client và skeleton server cho nhiều ngôn ngữ.
- Ví dụ ngôn ngữ: Java, Kotlin, Go, Python, C#, Node.js, Ruby, PHP… (tuỳ plugin).
- Lợi ích: một nguồn sự thật cho API; giảm lỗi tay khi viết client/server; đổi contract có kiểm soát (versioning).
Luồng: định nghĩa .proto → chạy protoc → import code sinh ra trong project.
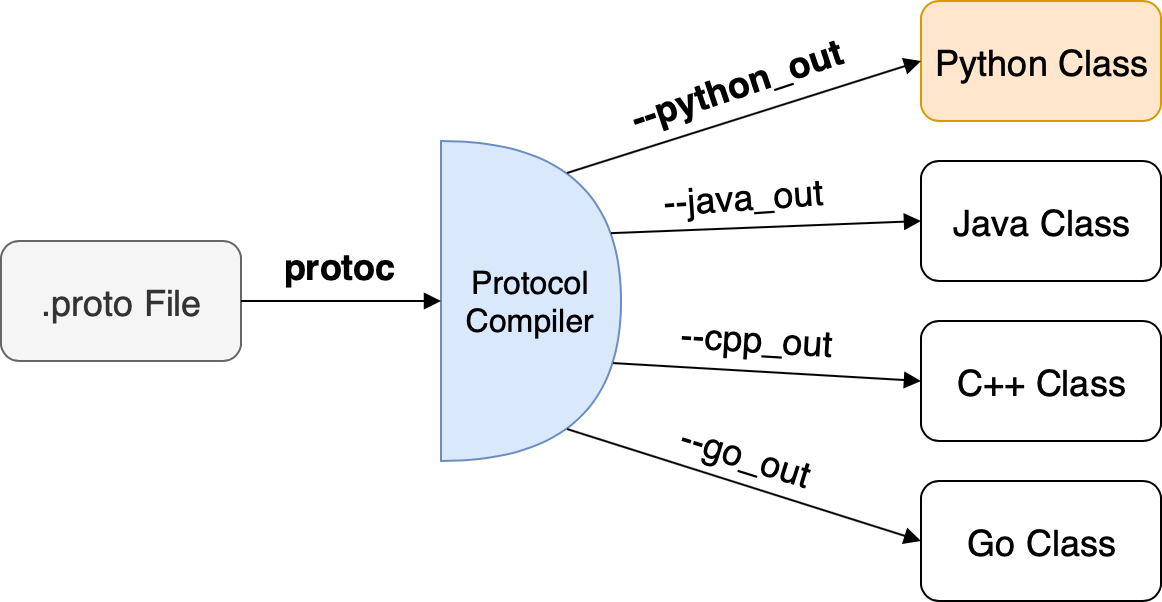
Mẫu: file .proto và lệnh sinh code
greeter.proto (định nghĩa service + message):
syntax = "proto3";
package demo;
// Service: compiler sẽ sinh GreeterStub (client) + GreeterServicer (server)
service Greeter {
rpc SayHello (HelloRequest) returns (HelloReply);
}
message HelloRequest {
string name = 1;
}
message HelloReply {
string message = 1;
}
Gợi ý lệnh (Python — cần grpcio-tools):
python -m grpc_tools.protoc -I . --python_out=. --grpc_python_out=. greeter.proto
Go (plugin protoc-gen-go + protoc-gen-go-grpc):
protoc --go_out=. --go_opt=paths=source_relative \
--go-grpc_out=. --go-grpc_opt=paths=source_relative greeter.proto
Sau khi chạy, project sẽ có các file *_pb2.py / *_pb2_grpc.py (Python) hoặc *.pb.go (Go) để implement server và gọi client.
REST vs gRPC: chọn thế nào?
| Tiêu chí | REST | gRPC |
|---|---|---|
| Client web/mobile | Rất tốt | Trung bình |
| Internal low latency | Khá | Rất tốt |
| Khả năng debug tay | Dễ | Khó hơn |
| Schema contract | Linh hoạt | Chặt chẽ |
Queue vs Pub/Sub

MQTT là gì? (Pub/Sub nhẹ cho IoT)
- MQTT (Message Queuing Telemetry Transport): giao thức pub/sub rất nhẹ, tối ưu cho thiết bị hạn chế và mạng không ổn định.
- Mô hình: publisher → broker → subscriber.
- Gửi theo topic dạng cây, ví dụ: factory/line1/temperature.
- Dùng nhiều cho telemetry/sensor, device status, command/control.
Broker phổ biến: Mosquitto, EMQX, HiveMQ (managed/enterprise).
MQTT: QoS, retained, Last Will (các “chi tiết” quan trọng)
- QoS 0: at most once (nhanh nhất, có thể mất).
- QoS 1: at least once (có thể gửi trùng → consumer cần idempotent).
- QoS 2: exactly once (đảm bảo cao hơn nhưng overhead lớn).
- Retained message: broker giữ message cuối của topic để subscriber mới nhận ngay “trạng thái hiện tại”.
- Last Will and Testament (LWT): nếu client rớt mạng, broker publish 1 message “tôi đã offline”.
# demo nhanh với Mosquitto (broker) + CLI tools
mosquitto_sub -t "factory/line1/temperature"
mosquitto_pub -t "factory/line1/temperature" -m "28.5"
Bảo mật: chạy qua TLS + auth (username/password hoặc mTLS) khi đưa vào production.
Mẫu kiến trúc giao tiếp hỗn hợp
4.
Thành phần hạ tầng cốt lõi
Load Balancing là gì?
- Định nghĩa: phân phối request/connection từ client tới nhiều instance backend.
- Mục tiêu: tăng availability, tăng throughput, giảm latency, tránh “một điểm nghẽn”.
- Health check: chỉ route vào instance “healthy”; instance lỗi sẽ bị loại khỏi pool.
- L4 vs L7: L4 cân bằng theo TCP/UDP; L7 cân bằng theo HTTP (host/path/header), hỗ trợ routing linh hoạt.
Ví dụ NGINX: L4 vs L7 Load Balancer
# /etc/nginx/nginx.conf
stream {
upstream grpc_backends {
server 10.0.0.11:50051;
server 10.0.0.12:50051;
}
server {
listen 50051; # cân bằng kết nối TCP
proxy_pass grpc_backends;
}
}
Không nhìn thấy HTTP path/header; chỉ cân bằng theo connection.
# /etc/nginx/nginx.conf
http {
upstream api_backends {
server 10.0.0.21:8080;
server 10.0.0.22:8080;
}
server {
listen 80;
location /api/ {
proxy_pass http://api_backends;
}
}
}
Có thể route theo URL/host/header; hợp API/Web.
Công nghệ Load Balancer phổ biến
- Cloud LB: AWS ALB/NLB, GCP Load Balancer, Azure Load Balancer.
- Self-managed: NGINX, HAProxy, Traefik, Envoy.
- K8s ingress controllers: NGINX Ingress, Traefik, Istio Gateway.
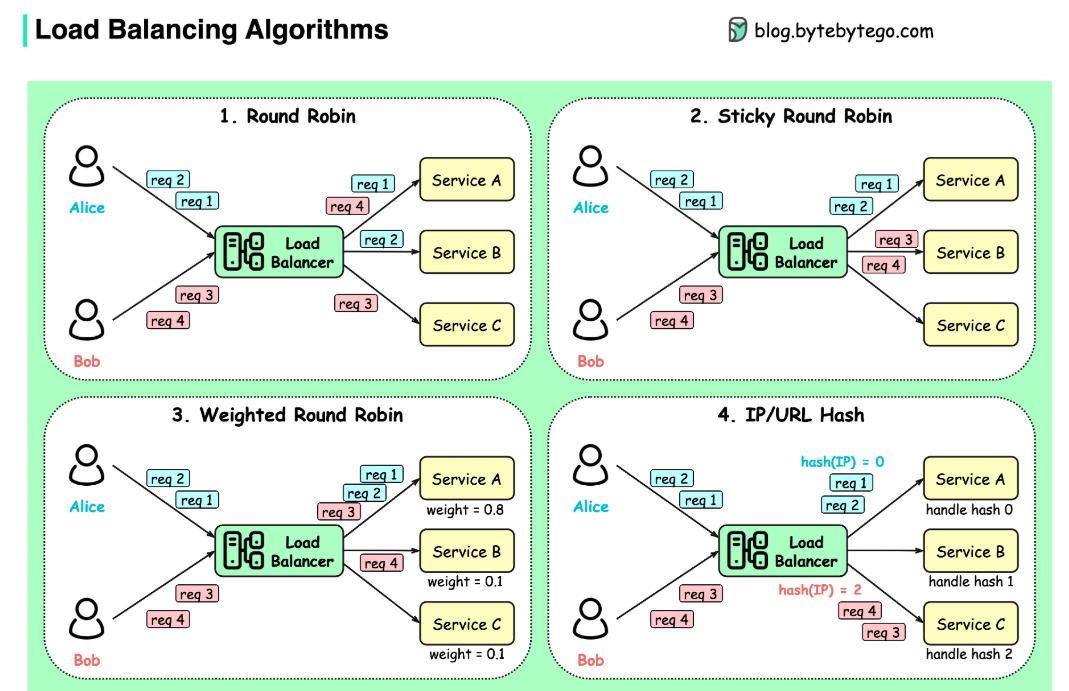
Thuật toán cân bằng tải phổ biến
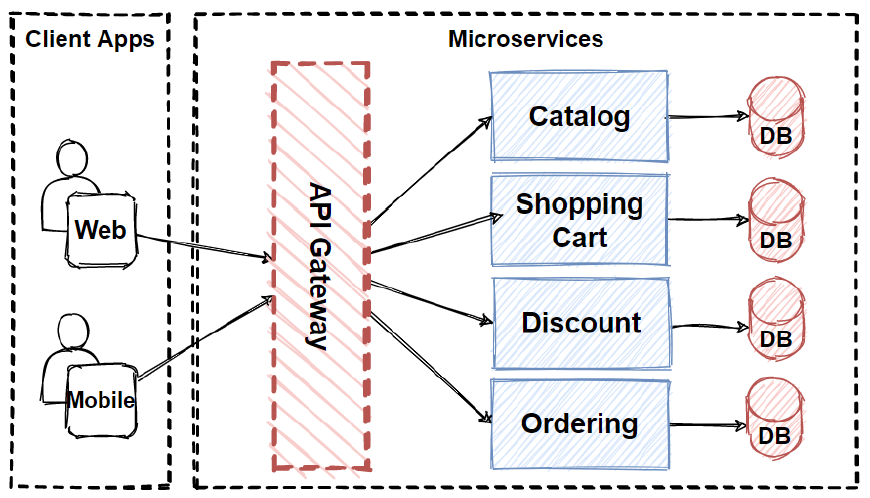
API Gateway
- Điểm vào thống nhất cho nhiều service phía sau.
- Chức năng: authN/authZ, rate limit, routing, transform, logging.
- Giảm phức tạp cho client.
API Gateway đặt ở đâu trong kiến trúc?
- Vị trí: “cổng” L7 ở biên hệ thống (edge) — trước các microservices.
- Client chỉ gọi 1 domain (ví dụ api.example.com), gateway route vào service phù hợp.
- Không thay thế LB: thường đi kèm LB/CDN/WAF; gateway tập trung vào policy và quản trị API.
- Gateway vs Reverse proxy: reverse proxy có thể làm gateway ở mức cơ bản; gateway “đúng nghĩa” có thêm plugin/policy, key management, analytics.
Hình dung: CDN/WAF → LB → API Gateway → services.
API Gateway làm những việc gì? (checklist)
- AuthN (Authentication): xác thực — API key, JWT/OAuth2, mTLS.
- AuthZ (Authorization): phân quyền — scope/role, RBAC/ABAC.
- Rate limit / quota: chống abuse, bảo vệ backend (ví dụ 100 req/phút/user).
- Routing: theo host/path/header; canary route theo % traffic.
- Transform: chuẩn hoá request/response, header mapping, versioning.
- Observability: access logs, tracing id, metrics theo route/tenant.
Minh họa API Gateway
Ví dụ policy ở Gateway (Kong / Envoy / NGINX)
# Ví dụ ý tưởng: route /api/v1/* → user-service, có auth + rate-limit
route:
match: { path_prefix: "/api/v1/users" }
upstream: "http://user-service:8080"
plugins:
- jwt_auth: { issuer: "https://auth.example.com" }
- rate_limit: { per_minute: 100, by: "consumer" }
- request_id: true
- cors: { allow_origins: ["https://app.example.com"] }
- Ý chính: policy để ở “cổng” → service phía sau tập trung business logic.
- Lưu ý: với nội bộ cluster, có thể tách API Gateway (edge) và Service Mesh (east-west).
Công nghệ API Gateway phổ biến
- Managed: AWS API Gateway, Apigee, Azure API Management.
- Open source: Kong Gateway, KrakenD, Tyk, Ambassador.
- Service mesh edge: Istio ingress gateway, Envoy-based gateway.
LB vs API Gateway
| Load Balancer | API Gateway | |
|---|---|---|
| Mục tiêu | Phân tải | Quản trị API |
| Tầng | L4/L7 | L7 |
| Tính năng | route cơ bản | auth, quota, policy |
Caching (Redis và các lớp cache)
- Giảm latency, giảm tải DB/backend.
- Lớp cache: client cache, CDN cache, application cache, DB cache.
- Redis thường dùng làm in-memory key-value store.
Cache: vì sao “nhanh hơn”?
- Nguyên lý: lưu kết quả/đối tượng “hay dùng” ở nơi truy cập nhanh hơn (RAM/edge) so với DB/disk/network.
- Đổi lại: phải xử lý staleness (dữ liệu cũ), invalidation, và consistency.
- Workload phù hợp: đọc nhiều hơn ghi, truy cập lặp lại (hot keys), dữ liệu có thể chấp nhận trễ nhẹ.
- Ví dụ: profile người dùng, config, feature lookup, kết quả query phổ biến.
“There are only two hard things in Computer Science: cache invalidation…”
Cache patterns
- Cache-aside
- Read-through / Write-through
- Write-behind
- TTL + invalidation strategy
Cache-aside (lazy loading) — luồng phổ biến
- App hỏi cache trước. Nếu hit → trả ngay.
- Nếu miss → query DB → trả kết quả → ghi vào cache (kèm TTL).
- Ưu: đơn giản, cache chỉ chứa dữ liệu thật sự được dùng.
- Nhược: miss đầu tiên chậm; dễ bị “thundering herd” nếu nhiều request miss cùng lúc.
Mitigation: request coalescing / lock theo key, hoặc warm-up cache.
TTL & Invalidation: chọn chiến lược
- TTL (Time To Live): dữ liệu tự hết hạn sau \(t\) giây/phút.
- Invalidation: khi dữ liệu gốc thay đổi → xóa/refresh cache theo key/tag.
- Trade-off: TTL ngắn → ít stale nhưng tốn tải; TTL dài → rẻ nhưng stale nhiều hơn.
- Cache stampede: nhiều key cùng hết hạn → spike DB. Cách giảm: jitter TTL, stale-while-revalidate.
Cache hit vs cache miss (ví dụ code)
def get_user_profile(user_id: str):
key = f"user:{user_id}:profile"
cached = redis.get(key)
if cached is not None:
metrics.inc("cache_hit", 1)
return json.loads(cached)
metrics.inc("cache_miss", 1)
profile = db.query_user_profile(user_id) # chậm hơn cache
# TTL 300s (5 phút); có thể thêm jitter để tránh stampede
redis.setex(key, 300, json.dumps(profile))
return profile
- Hit: đọc từ cache → nhanh (ms) và giảm tải DB.
- Miss: phải xuống DB → chậm hơn; sau đó “làm nóng” cache cho các request sau.
Theo dõi hit-rate = hit/(hit+miss) theo từng endpoint/key để quyết định có đáng cache không.
Công nghệ caching phổ biến
- In-memory: Redis, Memcached.
- HTTP cache: Varnish, NGINX cache.
- Application cache frameworks: Caffeine (Java), cachetools (Python).
- Distributed cache trên cloud: AWS ElastiCache, Azure Cache for Redis.
Event queue / streaming
- RabbitMQ: queue-centric, routing mạnh qua exchange.
- Kafka: log/event streaming throughput cao, retention tốt.
- Dùng cho async processing, decoupling, replay.
Công nghệ queue/event phổ biến
- Queue: RabbitMQ, ActiveMQ, AWS SQS.
- Streaming: Kafka, Redpanda, AWS Kinesis, Google Pub/Sub.
- Workflow/event orchestration: Temporal, Airflow, Argo Workflows.
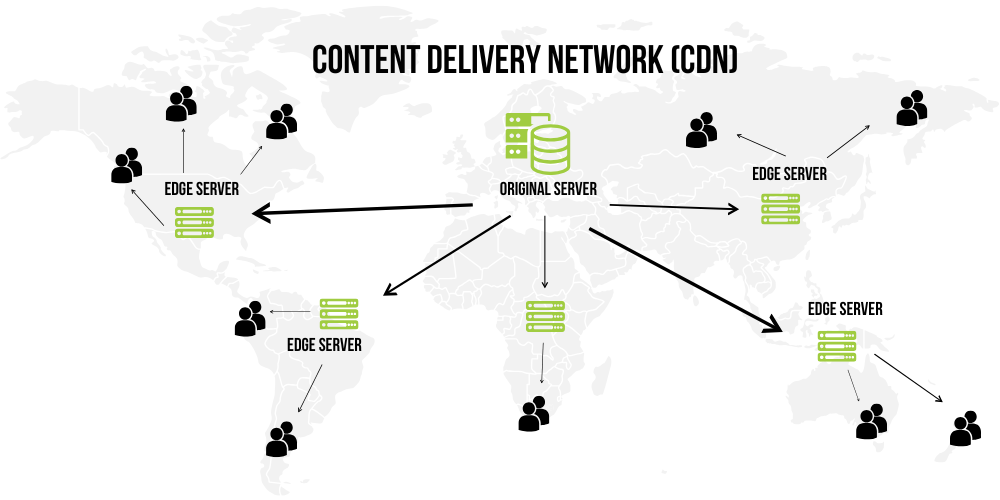
CDN là gì?
- Phân phối nội dung tĩnh qua edge nodes gần người dùng.
- Giảm latency toàn cầu, giảm tải origin.
- Rất quan trọng cho frontend assets, media, model docs.
CDN là gì?
Công nghệ CDN phổ biến
- Cloudflare CDN
- AWS CloudFront
- Google Cloud CDN
- Azure CDN
- Fastly, Akamai (enterprise)
VPS và VPN (khái niệm thường gặp)
- VPS (Virtual Private Server): máy chủ ảo riêng trên hạ tầng cloud/DC.
- VPN (Virtual Private Network): kênh mạng riêng, mã hóa giữa các mạng.
- Dùng để bảo vệ truy cập admin, kết nối private giữa môi trường.
SSH là gì? (truy cập admin an toàn)
- SSH (Secure Shell): giao thức để đăng nhập/điều khiển máy chủ từ xa qua kênh mã hóa.
- Thường dùng để quản trị VPS: deploy, xem log, restart service, cấu hình firewall…
- Xác thực: password (không khuyến nghị) hoặc SSH key (khóa công khai/riêng).
- Best practice: tắt password login, chỉ cho phép key + bật MFA ở tầng quản lý (cloud console/SSO).
# tạo key (Ed25519)
ssh-keygen -t ed25519 -C "admin@company"
# đăng nhập VPS
ssh -i ~/.ssh/id_ed25519 ubuntu@203.0.113.10
SSH tunneling: port forwarding (ví dụ)
- Local forward: mở cổng local → xuyên qua SSH → tới dịch vụ private (DB/Redis).
- Dùng khi DB chỉ mở trong VPC/private network; bạn truy cập qua bastion (jump host).
- Lưu ý: tunneling không thay thế VPN; phù hợp debug/ops, hạn chế quyền và audit.
# local port 15432 → (bastion) → private-db:5432
ssh -N -L 15432:private-db.internal:5432 ubuntu@bastion.example.com
# sau đó app local có thể connect: localhost:15432
psql "postgresql://user:pass@localhost:15432/appdb"
Mô hình phổ biến: Internet → Bastion (SSH) → private subnet (DB/Redis/K8s control-plane).
Ví dụ công nghệ VPS/VPN
- VPS: DigitalOcean Droplets, Linode, Vultr, EC2.
- VPN self-host: WireGuard, OpenVPN.
- Enterprise/managed: AWS Client VPN, Cloudflare Zero Trust.
Serverless (AWS Lambda)
- Chạy function theo event, không quản lý server trực tiếp.
- Trả phí theo mức sử dụng.
- Phù hợp xử lý ngắn, event-driven, bursty workload.
Công nghệ serverless phổ biến
- AWS Lambda
- Google Cloud Functions / Cloud Run
- Azure Functions
- OpenFaaS, Knative (self-host/Kubernetes)
Khi nào không nên serverless?
- Tác vụ chạy lâu hoặc cần GPU liên tục.
- Cold start không phù hợp SLA p95/p99 thấp.
- Stateful connection dài, yêu cầu control runtime sâu.
Monitoring và Observability
- 3 trụ cột phổ biến: metrics, logs, traces.
- Mục tiêu: phát hiện nhanh + khoanh vùng nhanh + sửa nhanh.
- Hệ microservices cần distributed tracing theo request-id.
Công nghệ monitoring phổ biến
- Metrics: Prometheus + Grafana, Datadog.
- Logs: ELK/EFK stack, Loki.
- Tracing/APM: OpenTelemetry, Jaeger, Zipkin, New Relic.
- Alerting/on-call: Alertmanager, PagerDuty, Opsgenie.
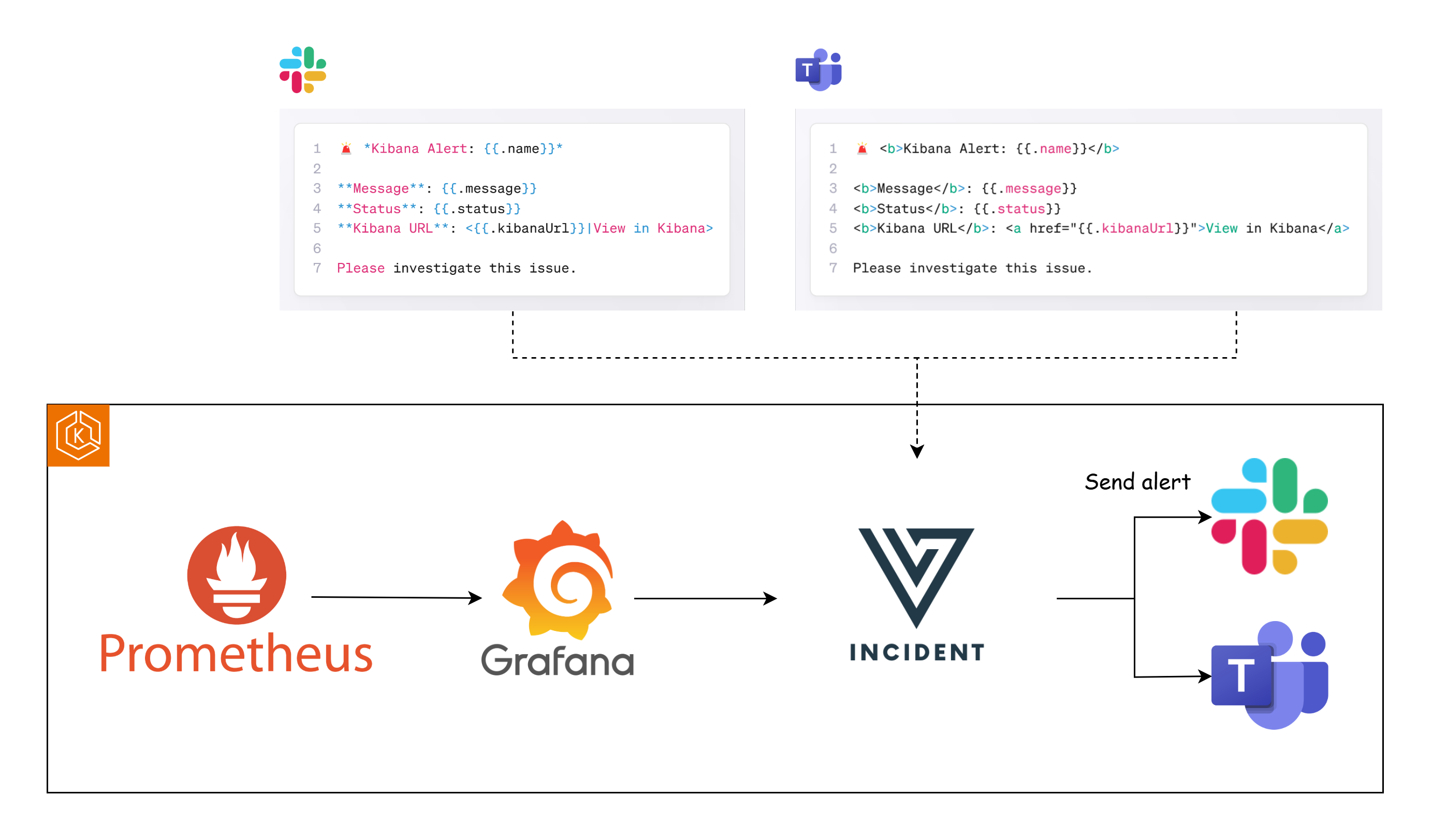
Alerting đúng cách
- Alert policy rõ ngưỡng và thời gian vi phạm.
- Notification đúng nhóm chịu trách nhiệm.
- Có runbook giảm alert fatigue.
5.
Database & Storage cho AI systems
Vai trò data layer trong kiến trúc
- Lưu trạng thái nghiệp vụ (OLTP).
- Lưu log, metadata, artifact model/dataset.
- Phục vụ analytics và pipeline ML (OLAP / lake khi cần).
Các loại database — tổng quan
- SQL (RDBMS): bảng + quan hệ, ACID, SQL chuẩn.
- NoSQL: document, key-value, wide-column, graph — linh hoạt schema / scale theo mô hình.
- Object storage: file/blob theo API (thường S3-compatible), không phải DB quan hệ.
- Vector DB: lưu và tìm kiếm theo embedding (similarity) cho RAG, gợi ý, tìm kiếm ngữ nghĩa.
SQL — Relational DB (RDBMS)
- Đặc điểm: schema cố định, khóa ngoại, transaction, ACID.
- Khi nào dùng: user, đơn hàng, thanh toán, dữ liệu quan hệ rõ.
- Ví dụ: PostgreSQL, MySQL/MariaDB; managed: RDS, Cloud SQL, Azure SQL.
- OLTP vs OLAP: OLTP = giao dịch nhanh; OLAP/warehouse = báo cáo (Snowflake, BigQuery…).
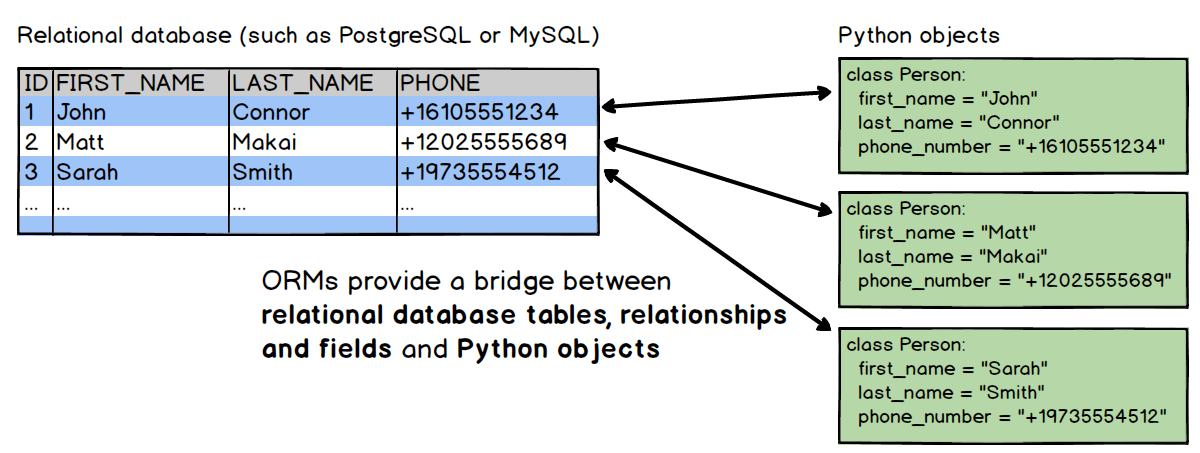
ORM là gì?
- Lợi ích: giảm boilerplate, migration/schema-as-code, type-safe (một số stack).
- Rủi ro: query “ẩn” kém hiệu năng nếu không hiểu SQL sinh ra.
ORM — cách hoạt động (ý tưởng)
- Model (class) ↔ Table; field ↔ cột.
- ORM dịch các thao tác lọc/lấy dữ liệu trong code → câu SELECT / JOIN tương ứng.
- Migration: đổi schema qua file versioned (Alembic, Django migrations, Prisma migrate…).
ORM
ORM — ví dụ stack thường gặp
| Ngôn ngữ / framework | ORM / layer | Ghi chú |
|---|---|---|
| Python + Django | Django ORM | Migration tích hợp |
| Python (FastAPI/Flask) | SQLAlchemy + Alembic | Linh hoạt, phổ biến backend hiện đại |
| Node.js | Prisma, TypeORM, Sequelize | Prisma: schema + generate type |
| Java | Hibernate / JPA | Enterprise |
| C# | Entity Framework | .NET |
ORM — N+1 query và cách tránh
- Lỗi phổ biến: vòng lặp khiến mỗi bản ghi cha gọi thêm query con → N+1 round-trip.
- Xử lý: eager loading — Django select_related / prefetch_related; SQLAlchemy joinedload; Prisma/TypeORM include.
- Luôn kiểm tra SQL thực tế (log, EXPLAIN) khi tối ưu production.
ORM tiện khi prototype; production cần chủ động index và kiểm soát query.
NoSQL — các mô hình
- Document: MongoDB, Couchbase — JSON/BSON, nested.
- Key–value: Redis, DynamoDB — cache, session, đơn giản theo khóa.
- Wide-column: Cassandra, HBase — write/scale phân tán.
- Graph: Neo4j, Neptune — mạng quan hệ.
NoSQL — khi nào cân nhắc
- Schema đổi nhanh hoặc dữ liệu bán cấu trúc.
- Scale ngang / pattern truy cập theo khóa rõ ràng.
- Trade-off: mô hình consistency khác SQL; thiết kế access pattern trước (đặc biệt DynamoDB/Cassandra).
[Vị trí ảnh: SQL vs NoSQL — use case]
Object storage & MinIO
- Object storage: bucket + key; API HTTP(S); dataset, ảnh, checkpoint, artifact ML.
- S3 là chuẩn thực tế; nhiều công cụ dùng SDK S3-compatible.
- MinIO: triển khai S3-compatible on-prem / private cloud; lab, air-gapped, chi phí dự đoán.
- Tích hợp MLflow, pipeline ML: artifact store trỏ MinIO hoặc S3.
[Vị trí ảnh: MinIO — bucket / kiến trúc]
Vector DB — vai trò trong AI
- Lưu embedding và similarity search (cosine, L2, inner product).
- RAG, tìm kiếm ngữ nghĩa, gợi ý, dedup.
- Bổ sung cho full-text search: ưu tiên “gần” trong không gian vector.
Vector DB — Milvus vs Qdrant
| Khía cạnh | Milvus | Qdrant |
|---|---|---|
| Hệ sinh thái | LF AI, hướng cluster/partition | Rust, REST/gRPC, deploy nhẹ |
| Đặc điểm | Metadata filter, nhiều loại index (HNSW, IVF…) | Filter + payload JSON, hybrid search |
| Gợi ý chọn | Workload lớn, team quen vận hành distributed | Prototyping nhanh, self-host đơn giản |
Tích hợp thường gặp: LangChain, LlamaIndex… [Vị trí ảnh: luồng embedding → Milvus/Qdrant → top-k]
6.
Mẫu kiến trúc theo kịch bản (AI systems)
Ý tưởng của mục này
- Không có “một kiến trúc đúng cho mọi hệ AI”.
- Mỗi kịch bản có nút thắt riêng: concurrency, latency, streaming, cost, tính nhất quán, quan sát.
- Ta chọn thành phần: CDN/LB/Gateway/Cache/Queue/DB/Vector DB/Monitoring… theo vấn đề cần giải.
Kịch bản 1: Online inference có nhiều user đồng thời
- Triệu chứng: QPS tăng, p95/p99 latency tăng, DB nóng, timeout.
- Mục tiêu: phục vụ nhanh, ổn định, autoscale, có rollback.
- Ví dụ: gợi ý sản phẩm, xếp hạng feed, fraud scoring realtime.
[Vị trí ảnh: kiến trúc online inference — CDN/LB/Gateway → inference → cache/DB]
Kịch bản 1: Kiến trúc gợi ý
- Edge: CDN/WAF → LB → API Gateway (auth, rate limit, routing).
- Inference service: stateless để scale ngang; timeout/retry/circuit breaker.
- Cache: cache-aside cho profile/feature/hot keys; giảm DB read.
- Data: SQL cho nghiệp vụ; NoSQL cho session; read replica nếu cần.
- Observability: tracing end-to-end (request id), p95/p99, saturation.
Pattern chính: rate limiting + caching + stateless scaling + graceful degradation.

Kịch bản 2: Streaming realtime (sự kiện liên tục)
- Triệu chứng: event đến liên tục, cần xử lý gần realtime; backlog tăng.
- Mục tiêu: throughput cao, xử lý bất đồng bộ, có replay, idempotent.
- Ví dụ: clickstream, IoT telemetry, log inference, feature streaming.
Kịch bản 2: Kiến trúc gợi ý
- Transport: Kafka / Pub/Sub / Kinesis; partition theo key để scale.
- Consumers: scale theo lag; xử lý idempotent (tránh double count).
- Stream processing: window/sliding aggregation (Flink/Spark Streaming) nếu cần feature realtime.
- Sink: ghi vào warehouse/lake + cập nhật cache/online store khi cần.
- Guardrails: backpressure, DLQ (dead-letter), schema registry/versioning.
Pattern chính: decoupling + replay + exactly/at-least-once trade-off.

Kịch bản 3: Batch scoring / Offline jobs
- Triệu chứng: job chạy định kỳ, xử lý dữ liệu lớn; không cần trả ngay.
- Mục tiêu: throughput + cost efficiency + reliability + retry.
- Ví dụ: chấm điểm toàn bộ user mỗi đêm, tạo embedding định kỳ, ETL/feature pipelines.
Kịch bản 3: Kiến trúc gợi ý
- Orchestrator: Airflow/Argo/Temporal — DAG + retry + backfill.
- Compute: Spark/Ray/Dask; autoscale theo batch size.
- Storage: object store (S3/MinIO) cho dataset/artifacts; warehouse cho analytics.
- Output: ghi kết quả vào DB/Redis để app đọc nhanh (batch-to-online).
- Data quality: schema checks, null rate, outlier; lineage để debug.
Pattern chính: “batch trước, online sau” (precompute) để giảm latency và cost.
Kịch bản 4: RAG / Tìm kiếm ngữ nghĩa (Vector DB)
- Triệu chứng: cần truy xuất “gần nghĩa” theo embedding + lọc theo metadata.
- Mục tiêu: top-k nhanh, cập nhật index hợp lý, quality + guardrails.
- Ví dụ: chatbot nội bộ, search tài liệu, semantic retrieval cho sản phẩm.
Kịch bản 4: Kiến trúc gợi ý
- Ingestion: crawl/ETL → chunk → embedding → upsert vào Milvus/Qdrant.
- Query: embed query → vector search top-k + metadata filter → rerank (tuỳ).
- Cache: cache embedding của query phổ biến / cache top-k.
- Observability: latency vector search, recall@k proxy, drift của embedding distribution.
- Safety: allowlist data sources, PII filtering, audit truy vấn.
Pattern chính: tách “index build” (offline/async) khỏi “retrieve” (online/low latency).

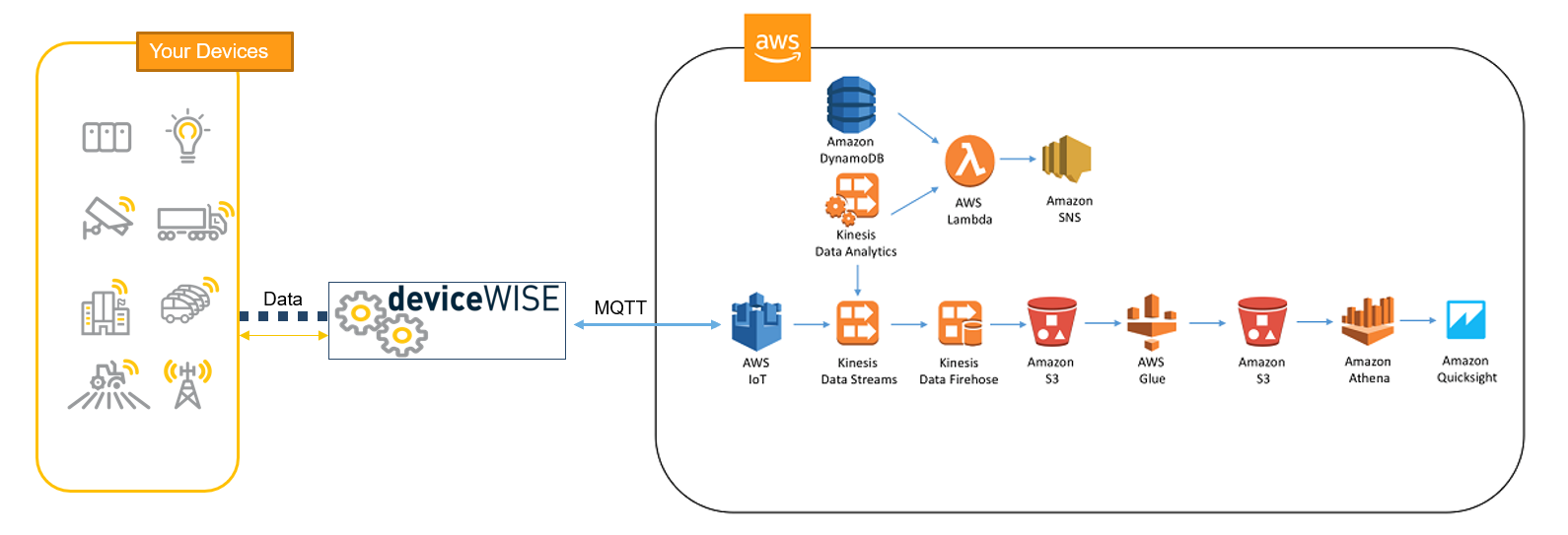
Kịch bản 5: Edge / On-device inference
- Triệu chứng: mạng không ổn định; cần phản hồi tức thì tại thiết bị.
- Mục tiêu: latency thấp, riêng tư dữ liệu, cập nhật model an toàn.
- Ví dụ: camera, mobile app, xe tự hành, kiosk/offline app.
[Vị trí ảnh: device inference — model on device + sync + telemetry]
Kịch bản 5: Kiến trúc gợi ý
- On-device runtime: TFLite / ONNX Runtime Mobile; quantization để chạy nhanh.
- Update: OTA model update theo phiên bản + rollout; rollback nếu lỗi.
- Telemetry: gửi log/metrics/feedback về server theo batch khi có mạng.
- Privacy: hạn chế gửi raw data; chỉ gửi thống kê/embedding (tuỳ chính sách).
- Fallback: nếu model lỗi → rule-based hoặc “cloud assist” khi có kết nối.
Pattern chính: tối ưu model + kiểm soát rollout + quan sát từ xa.
7.
Thiết kế theo giai đoạn trưởng thành
Giai đoạn 1: MVP
- Monolith + 1 DB + 1 queue đơn giản.
- Deploy nhanh, đo usage thật.
- Ưu tiên feedback loop với người dùng.
Giai đoạn 2: Growth
- Tách service nóng: auth, inference, billing.
- Thêm API gateway, cache, monitoring chuẩn hóa.
- Tăng độ tự động CI/CD.
Giai đoạn 3: Scale
- Microservices rõ bounded context.
- Event-driven cho nhiều luồng bất đồng bộ.
- DR strategy, multi-region cho workload quan trọng.
Anti-patterns thường gặp
- Tách microservices quá sớm.
- Không có observability nhưng hệ phân tán rộng.
- Đưa mọi thứ vào queue “cho dễ scale”.
- Không version API/schema/event.
Checklist chọn kiến trúc
- Traffic profile hiện tại và 12 tháng tới?
- Độ critical của tính năng AI?
- Năng lực đội vận hành hiện tại?
- Cost ceiling và SLO mong muốn?
- Ràng buộc pháp lý/bảo mật?
Bài tập tình huống 1
Bạn xây ứng dụng chatbot nội bộ cho 300 nhân viên:
- Nên bắt đầu monolith hay microservices?
- Thành phần nào bắt buộc ở bản v1?
- KPI kỹ thuật nào cần theo dõi tuần đầu?
Bài tập tình huống 2
Bạn có app gợi ý video tăng từ 5K lên 500K DAU:
- Dịch vụ nào cần tách trước?
- Queue nào phù hợp: RabbitMQ hay Kafka?
- Thiết kế cache chiến lược thế nào?
Tổng kết
- Software architecture cho AI phải theo system-wide view.
- Monolith vs Microservices là bài toán thời điểm và năng lực vận hành.
- REST/gRPC/event-driven nên kết hợp theo đúng use case.
- Các “khối lego” quan trọng: LB, API Gateway, cache, queue, CDN, serverless, monitoring, data layer.
- Kiến trúc tốt là kiến trúc cân bằng giữa latency, reliability, cost, tốc độ phát triển.
Gợi ý tự học sau buổi này
- Thiết kế 1 sơ đồ kiến trúc cho dự án AI bạn đang làm.
- Liệt kê 5 quyết định kiến trúc và trade-off tương ứng.
- Đề xuất lộ trình 3 giai đoạn: MVP → Growth → Scale.